






Dalam proses Data Mining, knowledge didapatkan setelah melalui beberapa tahapan yang dilakukan secara terstruktur terhadap sekumpulan data. Dapat dipastikan, betapa pentingnya data dalam proses ini. Oleh karena itu, pada artikel kali ini akan membahas dan mengenal data dalam proses Data Mining.
Objek Data dan Tipe Atribut
Data set terdiri dari objek data yang dimana tiap objek data mewakili sebuah entitas. Objek data dideskripsikan oleh atribut, yang jika direprersentasikan dalam bentuk tabel atribut terletak pada kolom sementara objek data terletak pada baris.
Atribut (dengan nama lain dimensions, features, variables) merupakan bagian dari data yang mewakili karakteristik dari objek data. Atribut memiliki beberapa tipe yang berbeda-beda, antara lain sebagai berikut.
- Nominal berkaitan dengan kategori atau nama-nama suatu benda. Contohnya alamat, hobi dan sebagainya.
- Binary hanya terdiri dari 2 jenis nilai yaitu 0 dan 1. Dimana 0 berarti 'tidak' dan 1 berarti 'ya'. Binary sendiri terbagi lagi menjadi 2 yaitu Symmetric binary, dimana outputnya memiliki nilai yang sama penting (contohnya laki-laki & perempuan) sementara asymmetric binary, outputnya tidak memiliki nilai yang sangat penting (contohnya positif & negatif).
- Ordinal memiliki urutan atau peringkat tetapi besar antar nilai yang berurutan tidak diketahui. Contohnya tingkat kepuasan. seperti tidak puas, netral, puas.
- Numeric: quantitative bermakna bahwa nilai atribut dapat diukur. Atribut numerik terbagi menjadi interval-scaled yang memiliki nilai yang tetap diantara tiap data interval atau ratio-scaled yang memiliki nilai 0.
Atribut Diskrit dan Kontinu
Selain memiliki tipe yang berbeda, atribut juga memiliki jenis yang dibedakan menjadi 2, yaitu sebagai berikut.
- Diskrit terdiri dari kumpulan nilai yang terbatas atau tak terbatas yang dapat dihitung. Atribut ini sering direpresentasikan dalam bentuk integer.
- Kontinu terdiri dari bilangan real. Atribut ini sering direpresentasikan dalam bentuk floating-point (desimal).
Similarity and Dissimilarity
Kembali ke objek data, terdapat istilah untuk melihat perbedaan antar objek data, diantaranya:
- Similarity untuk melihat kemiripan dua objek data. Biasanya menggunakan rentang 0 dan 1 yang jika bernilai lebih tinggi, maka objek data semakin mirip.
- Dissimilarity untuk melihat ketidakmiripan dua objek data. Biasanya berada pada rentang 0, dimana objek data akan semakin tidak mirip jika bernilai lebih rendah.
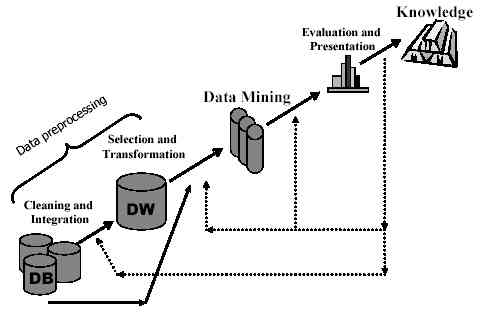
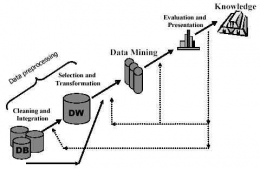
Dengan penjelasan di atas, kita telah mengetahui data dalam Data Mining. Selanjutnya akan dijelaskan tahapan dalam Data Mining yang dikenal dengan 'Knowledge Discovery In Databases (KDD)'. Adapun tahapannya sebagai berikut.
1. Database, berisi kumpulan data yang akan diolah.
2. Data Integration, menyatukan beberapa data yang diperoleh ke dalam Data Warehouse dengan format yang disepakati.
3. Data Cleaning, menghilangkan data - data yang tidak perlu atau mengisi data yang kosong. Biasa ditabulasikan dalam bentuk kolom dan baris.
3.1 Data Transformation, merubah data, contohnya data kontinu -> data diskrit.
4. Data Selection, menyeleksi data yang akan digunakan sesuai dengan kebutuhan.
5. Data Mining, proses yang menggunakan algoritma untuk melakukan Clasification, Clustering, atau Asosiation.
6. Pattern Evaluation, proses evaluasi untuk memperoleh pola yang tepat dan sesuai.
7. Knowledge Presentation, merupakan hasil akhir. Dimana data akan divisualisasikan sedemikian rupa sehingga pengguna dapat memahaminya.
Referensi :
Jenis-jenis Atribut Data dalam Data Mining
Data Mining: Concepts and Techniques
Follow Instagram @kompasianacom juga Tiktok @kompasiana biar nggak ketinggalan event seru komunitas dan tips dapat cuan dari Kompasiana. Baca juga cerita inspiratif langsung dari smartphone kamu dengan bergabung di WhatsApp Channel Kompasiana di SINI
