





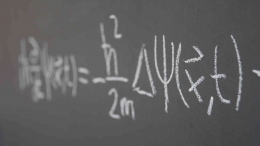
Kedua algoritma ini menunjukkan potensi besar dari quantum computing dalam memecahkan masalah kompleks dalam waktu yang jauh lebih cepat dibandingkan dengan komputasi klasik. Namun, saat ini, implementasi dari kedua algoritma ini masih memerlukan teknologi yang lebih maju dan sistem quantum computing yang lebih besar dan stabil.
III. Perbedaan Quantum Computing dan Komputasi Klasik
Kapasitas dan kompleksitas pemrosesan yang lebih tinggi
Kapasitas dan kompleksitas pemrosesan yang lebih tinggi adalah dua keuntungan utama dari quantum computing yang membedakannya dari komputasi klasik.
Kapasitas Pemrosesan yang Lebih Tinggi
Kapasitas pemrosesan yang lebih tinggi pada quantum computing dihasilkan oleh sifat-sifat kuantum yang memungkinkan qubit untuk berada dalam keadaan superposisi, di mana satu qubit dapat merepresentasikan nilai-nilai yang berbeda secara simultan. Hal ini memungkinkan sistem quantum computing untuk melakukan operasi pada banyak nilai secara paralel, yang menghasilkan kemampuan pemrosesan yang lebih cepat dan efisien.
Kompleksitas Pemrosesan yang Lebih Tinggi
Kompleksitas pemrosesan yang lebih tinggi pada quantum computing terkait dengan kemampuan sistem quantum computing untuk melakukan perhitungan pada banyak nilai secara paralel, yang menghasilkan kemampuan pemrosesan yang lebih efisien.
Algoritma-algoritma quantum computing seperti algoritma Shor dan algoritma Grover yang disebutkan sebelumnya memanfaatkan sifat-sifat kuantum untuk memecahkan masalah yang sulit secara efisien. Dalam beberapa kasus, quantum computing dapat memecahkan masalah yang dianggap sulit atau tidak dapat diselesaikan oleh komputasi klasik.
Namun, meskipun quantum computing memiliki potensi untuk memberikan kapasitas dan kompleksitas pemrosesan yang lebih tinggi, pengembangan teknologi quantum computing masih memerlukan penelitian dan pengembangan lebih lanjut.
Saat ini, sistem quantum computing masih memiliki keterbatasan dalam jumlah qubit yang dapat diproses secara efisien, serta masalah error dan decoherence yang dapat mempengaruhi akurasi hasil pemrosesan data.
IV. Kesimpulan
