






Crawling adalah aplikasi script program untuk melakukan scan kesemua halamandi internet dan dibuatkan index untuk data yang di carinya.
Nama lain untuk web crawl adalah web spider, web robot, bot, crawl dan automatic indexer.
Search engine menggunakan web crawl untuk mengumpulkan informasi mengenai apa yang ada di halaman-halaman web publik. Tujuan utamanya adalah mengumpukan data sehingga ketika pengguna Internet mengetikkan kata pencarian di komputernya, search engine dapat dengan segera menampilkan web site yang relevan.
Web crawl bisa beroperasi hanya sekali, misalnya untuk suatu projek yang hanya sekali jalan, atau jika tujuannya untuk jangka panjang seperti pada kasus search engine, mereka bisa diprogram untuk menyisir Internet secara periodik untuk menentukan apakah sudah berlangsung perubahan signifikan. Jika suatu situs mengalami trafik sangat padat atau kesulitan teknis, spider atau crawl dapat diprogram untuk mencatat hal ini dan mengunjunginya kembali setelah kesulitan teknis itu terselesaikan.
Secara sederhana proses Web Crawling dapat dijelaskan sebagai berikut; Diberikan sekumpulan URL yang disebut dengan seed set, kemudian secara multi-thread Web Crawler mulai dengan memilih salah satu URL di seed set tersebut. Selanjutnya Web Crawler mengunduh halaman web yang diacu oleh URL dan melakukan parsing. Isi halaman web yang merupakan konten (biasanya berupa teks) dipisahkan dari link yang terdapat di halaman itu. Teks yang telah dipisahkan diteruskan ke modul bernama text indexer yang nantinya akan melakukan indexing dan membentuk query. Sementara itu link yang telah dipisahkan dipindahkan ke URL Frontier, sebuah wadah yang berisi kumpulan URL yang berkorespondensi dengan halaman web utama. Dengan kata lain URL Frontier adalah sebuah sub seed set. Keseluruhan proses Web Crawling akan berulang secara rekursif. Suatu saat URL yang tersimpan di URL Frontier akan diambil dan ditelusuri lebih lanjut, dan pada akhirnya disimpan kembali untuk keperluan Web Crawling berkelanjutan di masa depan.
Algoritma dasar
Tahapan pembuatan crawling dengan menggunakan aplikasi VB.Net
User Interface Form :
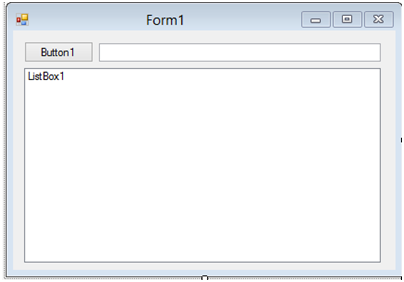
Keterangan :
Jenis Komponen
Nama
Text
Form
Form1
Form1
Button
Button1
Button1
TextBox
TextBox1
ListBox
ListBox1
Deklarasi.
Setelah selesai dengan design UI, dilanjutkan dengan membuat codenya, bukalah code designer dari Form1, kemudian ikuti imports item dan deklarasi seperti pada contoh berikut :
Code Form1
Imports System.Net
Imports System.IO
Imports System.Text.RegularExpressions
Public Class Form1
Dim LinkCollection As New Collection
Dim Depth As Integer = 5
Private Const Regex_Href_Code As String = "hrefs*=s*(?:""(?[^""]*)""|(?S+))"
End Class
Depth dengan nilai 5, variable ini berguna untuk membatasi kedalaman penelusuran link
Method ProcessLinkCollection.
Method ini akan digunakan untuk melakukan proses terhadap link - link yang diekstrak dari sebuah halaman web, berikut code nya :
Private Sub ProcessLinkCollection()
Depth = -1
For Each item In LinkCollection
LinkCollection.Remove(item)
ReadPageContent(item, TextBox1.Text)
Application.DoEvents()
Next
End Sub
Method ExtractURL.
Method ini digunakan untuk melakukan pemeriksaan terhadap conten web dan mengekstrak link - link yang terdapat pada halaman tersebut dan menyimpannya dalam sebuah object collection, berikut code nya :
Function ExtractURL(Content As String, URL As String) As Collection Dim UrlCollection As New Collection Dim BaseURI As New Uri(URL) Dim HrefRegex As New Regex(Regex_Href_Code, RegexOptions.IgnoreCase Or RegexOptions.Compiled) Dim HrefMatch As Match = HrefRegex.Match(Content) Do While HrefMatch.Success = True Dim Link As String = HrefMatch.Groups(1).Value If Link.Substring(0, 1) <> "#" Then Dim Absolute As Boolean = False If Link.Length > 8 Then UrlCollection.Add(Link) End If End If HrefMatch = HrefMatch.NextMatch Loop Return UrlCollection End Function
Method ReadPageContent.
Method ini merupakan method utama yang berguna untuk melakukan web request dan membaca conten page serta menyimpan link - link yang terdapat pada halaman yang di-request, selanjutnya method ini akan menampilkan link - link yang cocok dengan kriteria pencarian, berikut codenya :
Sub ReadPageContent(URL As String, SearchedText As String)
Dim BaseURI As New Uri(URL)
Dim PageContent As String = String.Empty
Try
Dim PageRequest As HttpWebRequest = CType(WebRequest.Create(BaseURI), HttpWebRequest)
Dim PageResponse As HttpWebResponse = PageRequest.GetResponse
Dim PageReader As New StreamReader(PageResponse.GetResponseStream)
PageContent = PageReader.ReadToEnd
LinkCollection = ExtractURL(PageContent, URL)
PageReader.Close()
If PageContent.Contains(SearchedText) = True Then
If Not ListBox1.Items.Contains(URL) Then ListBox1.Items.Add(URL)
Application.DoEvents()
End If
For Each item In LinkCollection
If Not ListBox1.Items.Contains(item) Then ListBox1.Items.Add(item)
Application.DoEvents()
Next
If Depth > 0 Then
ProcessLinkCollection()
End If
Catch ex As Exception
End Try
End Sub
Method Button1_Click.
Method ini adalah event triger untuk object button satu yang telah kita buat sebelumnya, berikut codenya :
Private Sub Button1_Click(sender As Object, e As EventArgs) Handles Button1.Click
ReadPageContent("https://www.google.com/search?q=" & TextBox1.Text, TextBox1.Text)
End Sub
Sumber : http://surya-pradhana.blogspot.com/2014/01/membuat-web-crawler-sederhana-dengan.html
Baca konten-konten menarik Kompasiana langsung dari smartphone kamu. Follow channel WhatsApp Kompasiana sekarang di sini: https://whatsapp.com/channel/0029VaYjYaL4Spk7WflFYJ2H
