







Pendahuluan
Pemrosesan bahasa alami (Natural Language Processing-NLP) adalah bidang yang berkembang pesat dalam kecerdasan buatan, dan Python menawarkan berbagai pustaka untuk membantu dalam analisis teks. Dua pustaka yang paling populer adalah NLTK (Natural Language Toolkit) dan spaCy. Meskipun keduanya digunakan untuk tujuan yang sama, mereka memiliki pendekatan yang berbeda. Artikel ini akan membahas beberapa perbedaan antara NLTK dan spaCy dengan menggunakan contoh kode.
Instalasi Library
Untuk menggunakan NLTK, Anda perlu menginstal pustaka dan mengunduh data tambahan yang diperlukan untuk pemrosesan teks. Berikut adalah contoh instalasi:
- !pip install scikit-learn pandas nltk openpyxl
- nltk.download('punkt')
Di sisi lain, spaCy memerlukan instalasi pustaka dan pengunduhan model bahasa yang akan digunakan. Proses ini lebih terintegrasi dan sederhana:
- !pip install spacy
- !python -m spacy download en_core_web_sm
Import Library
Kedua pustaka mengimpor pustaka yang sama, tetapi spaCy lebih fokus pada pemrosesan teks dengan model yang sudah dilatih. Berikut adalah contoh pengimporannya.
- import pandas as pd
- import nltk # Untuk NLTK
- import spacy # Untuk spaCy
Memuat Model
Setelah menginstal NLTK, Anda perlu mengunduh data yang diperlukan untuk tokenisasi dan pemrosesan lainnya. Sementara itu, Anda cukup memuat model bahasa dengan satu baris kode jika menggunakan spaCy, Ini menunjukkan bahwa spaCy lebih siap pakai untuk pemrosesan teks.
Preprocessing Teks
Dalam NLTK, preprocessing teks memerlukan beberapa langkah, termasuk tokenisasi menggunakan word_tokenize:
- def preprocess_text(text):
- text = re.sub(r'[^a-zA-Z0-9\s]', '', text) # Menghapus karakter non-alfanumerik
- tokens = word_tokenize(text.lower()) # Tokenisasi
- return tokens
Sebaliknya, spaCy menggunakan objek doc untuk memproses teks, yang secara otomatis menangani tokenisasi dan penghapusan stop words.
- def preprocess_text(text):
- text = re.sub(r'[^a-zA-Z0-9\s]', '', text) # Menghapus karakter non-alfanumerik
- doc = nlp(text.lower()) # Menggunakan spaCy untuk memproses teks
- return [token.text for token in doc if not token.is_stop and not token.is_punct]
Identifikasi Emosi
Kedua pustaka memiliki fungsi yang mirip untuk mengidentifikasi emosi, tetapi pendekatan spaCy lebih terintegrasi dengan pemrosesan teks yang lebih canggih. Berikut adalah contoh fungsi identifikasi emosi.
- def identify_emotions(text):
- tokens = preprocess_text(text)
- identified_emotions = set()
- for emotion, keywords in emosi_cowen.items():
- for keyword in keywords:
- if any(keyword in token for token in tokens):
- identified_emotions.add(emotion)
- return list(identified_emotions)
Ekstraksi Fitur
Kedua pustaka menggunakan TfidfVectorizer dari sklearn untuk ekstraksi fitur, menunjukkan bahwa mereka dapat digunakan bersama dengan alat pembelajaran mesin yang sama.
- vectorizer = TfidfVectorizer()
- X = vectorizer.fit_transform(data['respon'])
Evaluasi Model
Proses evaluasi model sama untuk kedua pustaka, menunjukkan bahwa meskipun pendekatan pemrosesan teks berbeda, mereka dapat digunakan dalam konteks yang sama untuk membangun dan mengevaluasi model pembelajaran mesin:
- print(classification_report(y_test, y_pred))
- print(confusion_matrix(y_test, y_pred))
Mana lebih unggul?
NLTK dan spaCy memiliki keunggulan masing-masing dalam pembelajaran mesin, tergantung pada kebutuhan pengguna. NLTK, yang dirancang untuk penelitian dan pendidikan, menawarkan fleksibilitas yang tinggi dan menyediakan berbagai alat untuk eksperimen dalam pemrosesan bahasa alami (NLP). Dengan koleksi algoritma dan fungsi yang luas, NLTK memungkinkan pengguna untuk melakukan berbagai tugas seperti tokenisasi, stemming, dan analisis semantik. Dokumentasi yang komprehensif dan banyak tutorial juga menjadikannya pilihan yang baik untuk pemula. Namun, NLTK cenderung lebih lambat dibandingkan spaCy, terutama saat memproses data dalam jumlah besar, dan lebih cocok untuk eksperimen akademis daripada aplikasi produksi.
Di sisi lain, spaCy dirancang untuk kecepatan dan efisiensi, menjadikannya ideal untuk aplikasi yang memerlukan pemrosesan teks yang cepat. Dengan pendekatan berbasis objek, spaCy memudahkan eksplorasi dan penggunaan, karena setiap fungsi mengembalikan objek yang kaya informasi. Selain itu, spaCy menyediakan model terlatih untuk berbagai tugas NLP, seperti pengenalan entitas dan analisis sintaksis. Meskipun sangat efisien, spaCy mungkin memiliki kurva pembelajaran yang lebih curam bagi pemula dan mungkin tidak menawarkan fleksibilitas yang sama seperti NLTK untuk eksperimen. Secara keseluruhan, pengguna disarankan untuk memilih NLTK jika ingin belajar dasar-dasar NLP dan melakukan eksperimen akademis, sementara spaCy lebih cocok untuk mereka yang membutuhkan alat yang cepat dan efisien untuk aplikasi produksi dan pemrosesan teks yang lebih besar.
Mungkin lebih bijak jika dipraktikkan saja. Hasil evaluasi kinerja dengan dataset yang sama menunjukkan perbedaan:
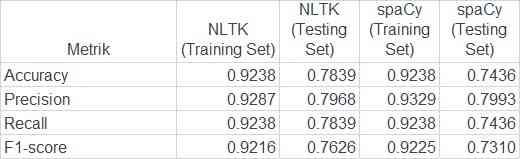
Perbandingan kinerja model menggunakan NLTK dan spaCy menunjukkan hasil yang menarik. Pada set pelatihan, kedua model memiliki akurasi yang sangat tinggi, masing-masing mencapai 92.38%, yang menunjukkan kemampuan mereka dalam memprediksi dengan benar sebagian besar data pelatihan. Namun, saat diuji pada set pengujian, NLTK menunjukkan akurasi yang lebih baik (78.39%) dibandingkan spaCy (74.36%), menandakan bahwa NLTK lebih efektif dalam generalisasi terhadap data yang belum pernah dilihat sebelumnya. Dalam hal precision, spaCy sedikit unggul pada set pelatihan dengan nilai 93.29% dibandingkan NLTK yang mencapai 92.87%, dan pada set pengujian, spaCy juga lebih baik dengan precision 79.93% dibandingkan NLTK yang 79.68%. Meskipun demikian, NLTK menunjukkan kinerja yang lebih baik dalam recall pada set pengujian, dengan nilai 78.39% dibandingkan 74.36% untuk spaCy, yang berarti NLTK lebih mampu menemukan contoh positif di data pengujian. F1-score, yang mencerminkan keseimbangan antara precision dan recall, juga menunjukkan keunggulan NLTK pada set pengujian (76.26%) dibandingkan spaCy (73.10%). Secara keseluruhan, meskipun kedua model menunjukkan kinerja yang baik, NLTK tampaknya lebih efektif dalam generalisasi dan menjaga keseimbangan antara precision dan recall pada data baru.
Penutup
Perbedaan antara NLTK dan spaCy mencerminkan tujuan dan filosofi desain masing-masing pustaka. NLTK lebih berfokus pada fleksibilitas dan pendidikan. NLTK dirancang untuk memberikan pengguna kontrol yang lebih besar dalam setiap langkah pemrosesan bahasa alami, memungkinkan kustomisasi alat dan teknik sesuai dengan kebutuhan spesifik proyek. Dengan menyediakan berbagai alat dan fungsi untuk tugas-tugas seperti analisis sintaksis, pengenalan entitas, dan analisis sentimen, NLTK memungkinkan pengguna untuk bereksperimen dengan berbagai pendekatan. Fleksibilitas ini menjadikannya pilihan yang ideal untuk penelitian dan eksperimen, di mana peneliti dapat dengan mudah mencoba berbagai algoritma dan teknik untuk menemukan yang paling efektif untuk dataset tertentu.
SpaCy memiliki pendekatan yang berbeda dibandingkan NLTK, dengan fokus pada efisiensi, kemudahan penggunaan, dan aplikasi industri. Dirancang untuk memproses teks dengan cepat dan efisien, spaCy sangat cocok untuk aplikasi dunia nyata, terutama saat menangani dataset besar. Antarmuka yang intuitif dan model bahasa yang sudah dilatih memungkinkan pengguna untuk melakukan pemrosesan teks dengan lebih sedikit kode, menghemat waktu dan usaha. Selain itu, spaCy menawarkan fitur canggih seperti Named Entity Recognition (NER) dan dependency parsing, serta integrasi yang baik dengan pustaka pembelajaran mesin lainnya. Meskipun sangat efisien, spaCy mungkin kurang fleksibel dibandingkan NLTK dalam hal kustomisasi, dan model yang disediakan mungkin tidak selalu sesuai dengan konteks spesifik. Secara keseluruhan, spaCy adalah pilihan yang baik untuk aplikasi yang memerlukan kecepatan dan kemudahan penggunaan, tetapi NLTK mungkin lebih sesuai untuk analisis yang lebih mendalam dan fleksibel.
Follow Instagram @kompasianacom juga Tiktok @kompasiana biar nggak ketinggalan event seru komunitas dan tips dapat cuan dari Kompasiana. Baca juga cerita inspiratif langsung dari smartphone kamu dengan bergabung di WhatsApp Channel Kompasiana di SINI
