










*Unsupervised Machine Learning melibatkan analisis data yang tak memiliki label untuk menggali pola, struktur, dan hubungan pada data tanpa adanya kolom ‘target’ (label).
*Pada supervised learning objektifnya adalah mempelajari hubungan antara fitur input dan output yang sesuai. →prediksi, klasifikasi. Sedangkan unsupervised learning bertujuan untuk mengeksplorasi dan memahami kemiripan karakteristik pada data. → eksplorasi, memahami data, mencari pola tersembunyi.
* Clustering digunakan untuk pengelompokan object-object data kedalam kelompok atau cluster yang tiap cluster memiliki object-object dengan tingkat kesamaan feature antar object yang tinggi.
• Algoritma clustering dapat digunakan untuk analisis cluster yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya.
• Analisis cluster mengklasifikasikan objek sehingga setiap objek yang paling dekat kesamaannya dengan objek lain berada dalam cluster yang sama.
* Ada beberapa pendekatan yang digunakan algoritma clustering untuk mengelompokkan object-object ke dalam tiap cluster:
1. Pendekatan Partisi
Clustering dengan pendekatan partisi atau sering disebut dengan partition-based clustering mengelompokkan data dengan memilah-milah data yang dianalisa ke dalam cluster-cluster yang ada.
contoh : K-Means
2. Pendekatan Hirarki
Clustering dengan pendekatan hirarki atau sering disebut dengan hierarchical. clustering mengelompokkan data dengan membuat suatu hirarki berupa dendogram dimana data yang mirip akan ditempatkan pada hirarki yang berdekatan dan yang tidak pada hirarki yang berjauhan.
contoh : Agglomerative Hierarchical Clustering
3. pengelompokkan berbasis kepadatan, pendekatan ini tidak mengharuskan pengguna menentukan jumlah cluster, namun ada parameter berbasis jarak yang bertindak sebagai ambang batas ini menentukan sebereapa dekat titik-titik tersebut agar dapat dianggap sebagai anggota klaster.
contoh: DBSCAN, OPTICS.
*Konsep perhitungan jarak umum yang digunakan untuk menghitung menggunakan formula:
1. Manhattan Distance:
- Juga dikenal sebagai L1 distance.
- Mengukur jarak antara dua titik dalam ruang dengan menghitung total perbedaan absolut antara koordinat mereka.
- Dalam 2D, Manhattan distance adalah jumlah vertikal dan horizontal yang harus ditempuh untuk berpindah dari satu titik ke titik lain.
- Rumus:
 sumber: rumus Manhattan Distance
sumber: rumus Manhattan Distance
2. Euclidean Distance:
- Juga dikenal sebagai L2 distance.
- Mengukur jarak antara dua titik dalam ruang dengan menggunakan teorema Pythagoras.
- Rumus:
 sumber: Rumus Euclidean Distance
sumber: Rumus Euclidean Distance
3. Minkowski Distance:
- Generalisasi dari Manhattan dan Euclidean distance.
- Bergantung pada parameter (p).
- Ketika (p = 1), Minkowski distance sama dengan Manhattan distance.
- Ketika (p = 2), Minkowski distance sama dengan Euclidean distance.
- Rumus:
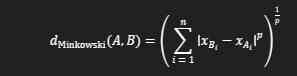
#sebenarnya banyak sekali konsep perhitung jarak, namun yang paling sering digunakan adalah Euclidean Distance.
* mengapa clustering digunakan ? Untuk mempermudah pengelompokkan objek-objek data yang banyak, lebih dari dua variabel.
- K-means adalah metode clutering yang menggunakan centroid (pusat data) sebagai titik yang representatif terhadap data disekelilingnya. (harus mengetahui/menentukan jumlah kelompok)
- Kelebihan:
komputasi cenderung ringan dan dapat menangani dataset yang besar
mudah diimplementasikan dan dipahami
performanya bagus jika cluster yang terbentuk terlihat perbedaannya
Kekurangan:
perlu menentukan jumlah cluster sebelum menjalankannya
sensitif terhadap pilihan awal centroid pada cluster, dapat menghasilkan centroid yang berbeda setiap kali dijalankan
menggunakan asumsi bahwa cluster berbentuk bulat dan memiliki varians yang mirip
- Kelebihan:
- Hierarchical Clustering adalah metode yang menciptakan struktur hierarki untuk membentuk cluster berdasarkan kriteria spesifik pada setiap tahap hierarkinya.
- Kelebihan:
Tidak perlu menentukan jumlah cluster diawal
menghasilkan struktur hierarki pada data, memberikan kebebasan untuk memilih level yang berbeda
dapat menangani cluster yang berbentuk dan berukuran berbeda
Kekurangan:
proses komputasinya berat, terutama untuk dataset yang besar
Interpretasi hasil clustering dapat bersifat subjektif, karena pemilihan tingkat clustering mempengaruhi jumlah dan komposisi cluster
- Kelebihan:
- Density-Based spatial clustering of Application with Noise (DBSCAN) adalah algoritma clustering yang mengelompokkan setiap data berdasarkan kepadatan datanya, dan membiarkan data yang jauh dari titik lainnya menjadi noise.
- Kelebihan:
dapat mengelompokkan cluster dengan bentuk yang tidak wajar dan mampu menangani kepadatan yang beragam secara efektif
tidak perlu menentukan jumlah cluster diawal
dapat mendeteksi outlier sebagai titik noise, dan memberikan insight pada data yang anomali
Kekurangan:
bergantung pada pemilihan jarak dan kepadatan data (termasuk jumlah minimal anggota cluster), yang memerlukan perkiraan terlebih dulu
kesulitan menangani dataset yang memiliki kepadatan data beragam
- Kelebihan:
Baca konten-konten menarik Kompasiana langsung dari smartphone kamu. Follow channel WhatsApp Kompasiana sekarang di sini: https://whatsapp.com/channel/0029VaYjYaL4Spk7WflFYJ2H
