




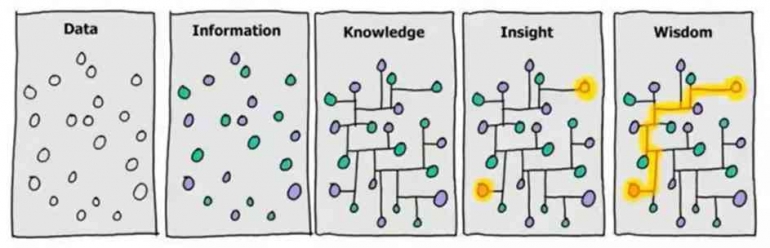







Data mining pasti berhubungan dengan data set atau himpunan data seperti yang sudah saya jelaskan dalam tulisan saya sebelumnya "Mengenal Komponen dalam Proses Data Mining". Dalam dunia data mining, himpunan data biasanya dikategorikan menjadi dua itu data numerik (data yang dapat dilakukan operasi pertambahan, pengurangan, perkalian serta pembagian) dan data nominal (data yang tidak dapat dilakukan operasi pertambahan, pengurangan, perkalian serta pembagian). Pengkategorian data ini sangat penting untuk dilakukan karena dari proses kita dapat menentukan apakah sebuah himpunan dapat di proses dengan data mining roles tertentu, apakah suatu himpunan data dapat diproses dengan metode estimasi atau tidak. Untuk lebih jelasnya akan diuraikan sebagai berikut.
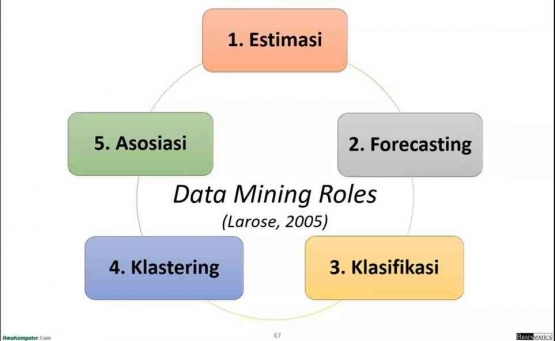
1. Estimasi
Estimasi merupakan metode dalam data mining yang dapat digunakan untuk memperkirakan nilai populasi dengan memakai nilai sampel. Estimasi hanya dapat bekerja apabila data set yang dijadikan sampel memiliki variable target yang bersifat numerik (bilangan/kontinu). Estimasi nilai dari variable target, ditentukan berdasarkan nilai dari variable predictor (atribut). Algoritma dalam metode estimasi adalah :
- Linear Regression
- Neural Network
- Support Vector Machine
2. Forecasting
Forecasting atau biasa disebut dengan prediksi merupakan metode yang digunakan untuk melakukan perkiraan/prediksi suatu nilai yang akan dicapai dalam suatu periode waktu. Forecasting hampir sama dengan estimasi, yang membedakannya adalah dalam forecasting data yang digunakan merupakan data rentet waktu (data time series). Algoritma dalam metode forecasting salah satunya adalah Statistical And Logistic Regression
3. Klasifikasi
Klasifikasi adalah metode data mining yang menggunakan data dengan target berupa nilai kategori. Adapun algoritma dalam metode klasifikasi yang paling sering digunakan adalah :
- Naive Bayes
- K-Nearest Neighbour
- C4.5
- ID3 (Iterative Dichotomiser 3)
- CART (Classification And Regression Tree)
- Linear Discriminant Analysis
- Decission Tree
4. Klastering
Klastering merupakan pengelompokkan data hasil observasi/penelitian yang tujuannya untuk memetakan data pada kelompok atau cluster tertentu berdasarkan tingkat kemiripannya dengan data lain. Salah satu algoritma metode klastering yang paling umum digunakan adalah k-Means.
5. Asosiasi
