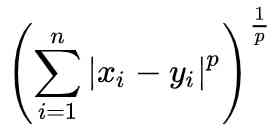4. Hierarchical visualization techniques
5. Visualizing complex data and relations
Mengukur Kesamaan & Ketidaksamaan Data
Sebelum memulai topik ini pertama-tama harus diketahui terlebih dahulu istilah yang berkaitan yaitu yang pertama ada similarity/kesamaan data adalah pengukuran seberapa tinggi tingkat kesamaan dari dua objek data. Nilai dari similarity ini akan semakin tinggi (range value [0,1]) jika objek data semakin tinggi tingkat kemiripannya. Yang kedua ada dissimilarity/ketidaksamaan data yang merupakan kebalikan dari similarity dimana dilakukan pengukuran seberapa tinggi tingkat ketidakmiripan dua objek data. Nilai dissimilarity akan menurun ketika objek data yang diamati semakin mirip. Minimum dissimilarity berkisar di angka 0 sedangkan untuk nilai maximumnya bervariasi. Kemudian yang terakhir ada proximity yaitu pengukuran untuk menghitung jarak antar data yang akan mengidentifikasi suatu data memiliki tingkat kesamaan yang tinggi atau tidak terhadap data lain.
Untuk menghitung atau mengukur tingkat kesamaan/ketidaksamaan data, ada beberapa metode pengukuran yang dapat digunakan :
1. Euclidean Distance

2. Manhattan Distance

3. Minkowski Distance