



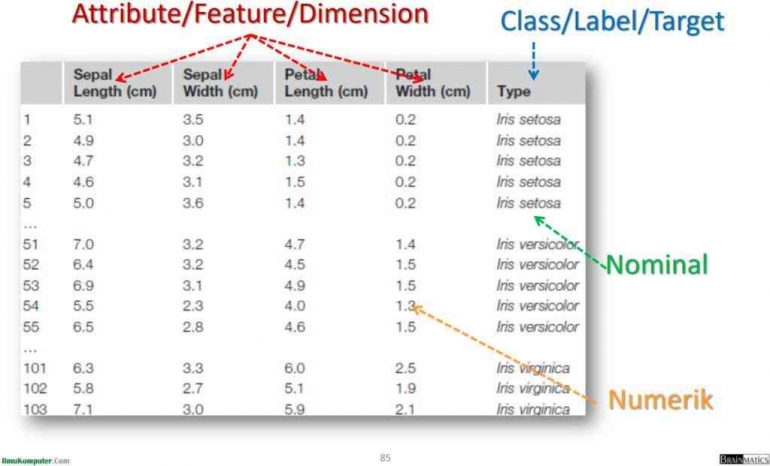











Pada tulisan sebelumnya sudah di bahas mengenai apa itu data mining. Data mining adalah proses pengolahan data dengan ruang lingkup data yang besar untuk di ekstrak menjadi informasi yang berguna untuk di jadikan dasar dalam suatu pengambilan keputusan. Dalam proses mining data hal yang pertama disiapkan adalah dataset atau himpunan data/objek data. Objek data digambarkan dengan menggunakan sejumlah atribut yang mewakili karakteristik dari objek data tersebut.
Objek Data & Tipe Atribut
Dikutip dari Repository Dinus tentang data mining, dimana dijelaskan tentang komponen dari dataset sebagai berikut.
1. Attribute/Feature/Dimension
Atribute/atribut adalah sifat dari suatu objek data yang nilainya bisa bermacam-macam diantara objek-objek data yang diamati. Sederhananya atribut merupakan faktor atau parameter yang menyebabkan class/label/target terjadi. Contoh atribut misalnya rata-rata tinggi dan berat badan siswa kelas A dibandingkan dengan siswa kelas B. Attribute atau atribut dibagi menjadi 2 yaitu :
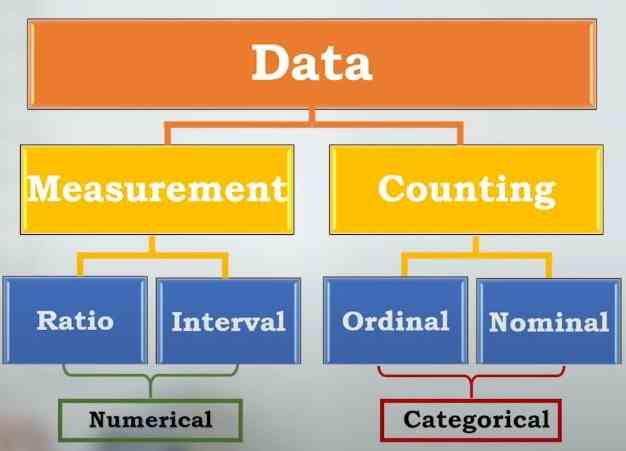
- Measurement/Numerik/Kuantitatif adalah data yang disajikan dalam bentuk angka yang bersifat terstruktur atau berpola. Tipe data measurement dapat diukur dan dapat dilakukan operasi matematik terhadap data tersebut. Hasil pengukuran panjang dari komponen bunga iris pada gambar 1 merupakan contoh dari data measurement/numerik. Data measurement mencakup data interval dan data rasio.
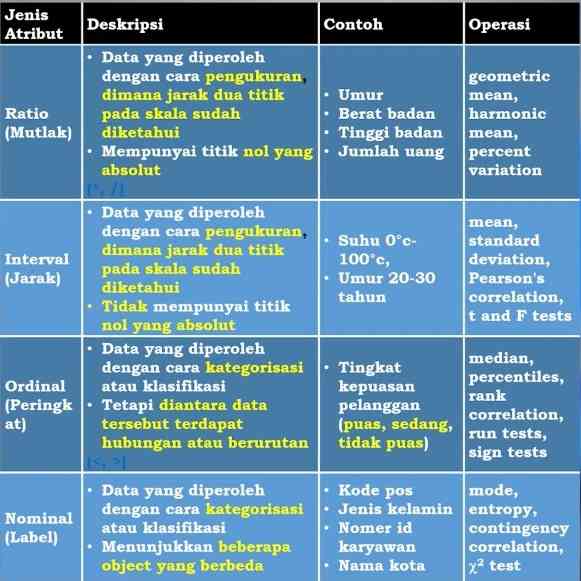
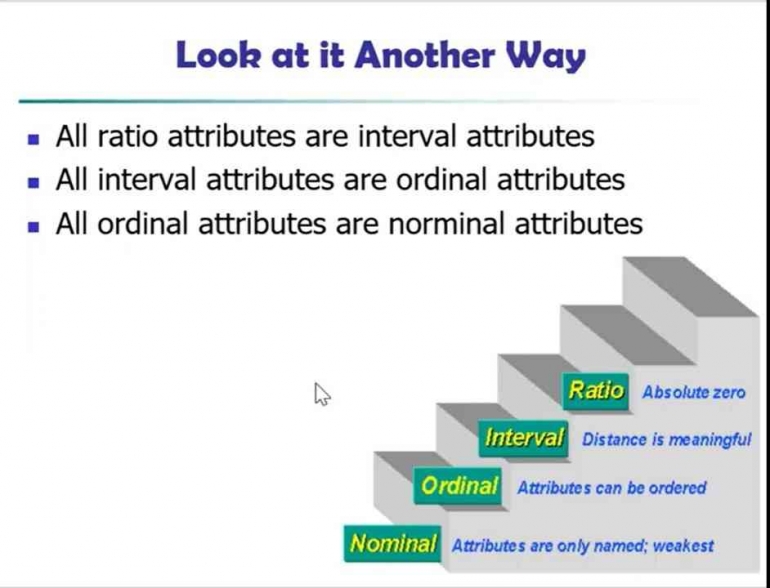
- Ratio/Rasio, perbandingan suatu nilai dimana jika dilakukan perhitungan berskala rasio antara dua nilai maka antara kedua nilai ini dapat dikatakan menjadi kelipatan (rasio) dari nilai lainnya. Contohnya terdapat data perhitungan panjang petal bunga iris setosa yaitu 10 cm dan panjang petal bunga iris versicolor yaitu 20 cm maka jika di hitung scala rasio, panjang petal bunga iris setosa dan iris versicolor dapat dikatakan panjang petal bunga iris versicolor adalah 2 kali panjang petal bunga iris setosa. Data rasio dapat divisualisasikan dengan simbol (*, /).
- Interval, perbedaan jarak dari dua nilai atribut. Contoh interval misalnya tanggal, temperatur, rating IQ, dsb. Data interval dapat divisualisasikan dengan simbol (+, -).
- Counting/Diskrit/Kualitatif adalah data non-numerik yang datanya dapat di catat, di amati dan mencirikan sesuatu. Tipe data ini dibagi lagi menjadi 2 yaitu ordinal dan nominal.
- Ordinal, nilai atribut berupa nama yang memiliki arti informasi terurut, misalnya konsisi barang (istimewa, baik, sedang, cukup, dsb) dapat divisualisasikan dengan simbol (<, <=, >=, >).
- Nominal, nilai atribut berupa nama yang membedakan dengan nilai lainnya (kategorik). Data ini diperoleh dari proses pengelompokkan beberapa objek yang berbeda berdasarkan kategori tertentu. Contoh data nominal misalnya jenis bunga seperti gambar di atas yaitu jenis bunga iris setosa, iris versicolor dan iris virginica. Data nominal dapat divisualisasikan dengan simbol (=, <>).
- Binary, nominal atribut yang hanya memiliki 2 nilai yaitu 0 dan 1. Data binary terbagi menjadi 2 yaitu symmetric binary (nilai hasil analisis data dengan skala binary akan equally important untuk semua hasil analisis data, contohnya gender) dan asymmetric binary (nilai hasil analisis data dengan skala binary tidak akan equally important, dimana hasil data analisis akan di golongkan kedalam 2 kategori yaitu positif dan negatif seperti hasil tes kesehatan, dsb).
2. Class/Label/Target adalah atribut yang akan dijadikan target untuk mengklasifikasikan objek data.
Diantara tipe atribut di atas, dalam proses mining data sering di gunakan cara lain untuk mendeskripsikan tipe atribut. Beberapa tulisan mengenai data mining disebutkan istilah 'discrete attribute/atribut diskrit' atau 'continuous attribute/atribut kontinu'. Atrubut diskrit dapat diprediksi menggunakan metode klasifikasi sedangkan untuk atribut kontinu dapat di prediksi menggunakan metode regresi.
