



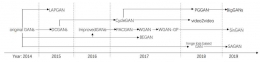

Penyatuan Generator dan Diskriminator
Fungsi tujuan GAN adalah kunci utama untuk melatih model generator dan diskriminator untuk mencapai kesetimbangan Nash. Maksudnya adalah generator dapat menangkap distribusi data yang sebenarnya, sementara diskriminator secara akurat membedakan antara sampel yang dihasilkan dan yang benar. Artikel ini menjelaskan evolusi fungsi tujuan GAN dan juga mencatat masalah yang dihadapi oleh fungsi tujuan asli, seperti hilangnya gradien dan runtuhnya mode. Fungsi tujuan GAN asli meminimalkan divergensi Jensen-Shannon antara distribusi data sebenarnya dan yang dihasilkan. Namun, ada tantangan seperti hilangnya gradien dan runtuhnya mode. Solusi seperti LSGAN yang mengadopsi kerugian kuadrat terkecil adalah salah satu upaya untuk mengatasi masalah ini.
GAN dalam Deteksi Objek: Generasi Realisme dalam Keadaan yang Tidak Biasa
Deteksi Objek dengan Sentuhan GAN
Saat kita membahas aplikasi GAN, salah satu yang menonjol adalah penggunaannya dalam deteksi objek. GAN membantu dalam menghasilkan contoh objek yang menghadapi tantangan seperti deformasi dan oklusi, yang sulit diklasifikasikan oleh detektor objek. Ini membantu dalam melatih detektor objek yang lebih tangguh dalam mengatasi situasi yang beragam. Segan dan MTGAN adalah varian GAN yang diadaptasi untuk mengatasi masalah deteksi objek kecil.
Berbagai Algoritma Generatif: Eksplisit dan Implisit
Model Kepadatan Eksplisit vs. Implisit
Saat berbicara tentang algoritma generatif, kita dihadapkan pada dua kelas utama: model kepadatan eksplisit dan implisit. Model kepadatan eksplisit secara eksplisit menggambarkan distribusi probabilitas data, sementara model kepadatan implisit mempelajari menghasilkan sampel dari distribusi data tanpa mendefinisikan fungsi distribusi. GAN adalah salah satu contoh model kepadatan implisit yang mendapatkan banyak perhatian karena kemampuannya mengatasi distribusi data yang kompleks.
Model Kepadatan Eksplisit: Tantangan Representasi yang Lebih Rinci
Estimasi Kemungkinan Maksimum dan Rantai Markov
Model kepadatan eksplisit memiliki keuntungan dalam mewakili distribusi data dengan rinci dan ekspresif. Artikel ini membahas pendekatan seperti Estimasi Kemungkinan Maksimum (MLE) dan Rantai Markov dalam model kepadatan eksplisit. Namun, ada tantangan seperti model yang terlalu halus, kesulitan dalam optimasi, dan kompleksitas komputasi yang tinggi yang terkait dengan pendekatan ini.
