





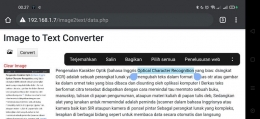


Untuk membuat layanan OCR berbasis PHP, kita bisa memanfaatkan antara lain Tesseract OCR for PHP.
Mengolah Data Ekstraksi dari KTP-el
Berikut contoh hasil ekstraksi teks dari foto KTP-el yang saya olah menggunakan Teserract OCR.

Proses perekaman dari kamera atau scanner tentu saja berperan sangat penting. Semakin jelas gambar yang dihasilkan maka akan semakin akurat teks yang dihasilkan. Termasuk susunannya.
Jika kualitas foto yang kita unggah tidak baik, dapat menyebabkan beberapa bagian teks menjadi tidak terbaca dan atau dihasilkan menjadi teks yang berbeda.
Tesseract OCR akan memberikan hasil ekstraksi berupa plain text. Kita mesti membuat algoritma atau rumusan sendiri untuk mengolah plain text tersebut sehingga dapat menghasilkan data yang kita inginkan seperti NIK, Nama, Tempat dan Tanggal Lahir, dan sebagainya.
NIK
Tesseract OCR mendukung berbagai macam teks dan bahasa, termasuk teks atau bahasa Arab, Jepang, India dan China.
KTP-el sendiri menggunakan huruf latin bahasa Indonesia. Namun, khusus untuk penulisan NIK menggunakan huruf atau karakter OCR-A yang memang dibuat untuk keperluan OCR.
Digitalisasi Dokumen
Selain dimanfaatkan untuk keperluan aplikasi seperti untuk membaca data KTP-el tersebut, secara umum Tesseract OCR, sebagaimana fungsinya, dapat kita manfaatkan sebagai tools digitalisasi berbagai macam dokumen, seperti untuk menyalin buku cetak menjadi buku digital, memindai tulisan pada poster dan lain sebagainya.
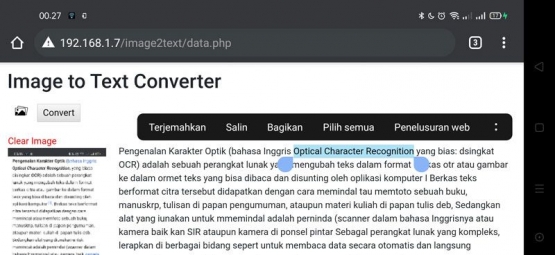
Demikian, mudah-mudahan bermanfaat. Di bagian bawah saya lampirkan juga tautan yang dapat Anda pelajari untuk menggunakan Tesseract OCR. Jika belum cukup, Anda bisa menanyakannya lebih lanjut ke mbah Google.
