


















Abstrak
Game, sebagai bentuk hiburan, diminati oleh berbagai kalangan, termasuk anak-anak, remaja, dan orang dewasa. Game Online merupakan salah satu bentuk hiburan yang telah menjadi bagian tak terpisahkan dari beragam lapisan masyarakat. Sebagai sebuah platform permainan daring yang menarik, game memungkinkan para pemainnya untuk tetap berinteraksi secara sosial. Salah satu contohnya adalah Genshin Impact, sebuah game mobile yang juga tersedia di platform PC dan PlayStation. Meskipun sebagian besar masyarakat menikmati permainan ini, ada pula yang merasa tidak sepenuhnya puas dengan pengalaman bermainnya. Analisis sentimen menjadi alat yang sangat berharga bagi pengembang game untuk memahami opini pengguna terhadap permainan tersebut. Penelitian ini bertujuan untuk membangun sebuah model klasifikasi ulasan terhadap Genshin Impact di Google Play, sehingga hasilnya dapat memberikan rekomendasi kepada Developer HoYoverse untuk perbaikan lebih lanjut.
Kata kunci: Analisis Sentimen, Genshin Impact, Nave Bayes
Abstract
Games are one of the preferred forms of entertainment across various age groups, ranging from children and teenagers to adults. Online gaming has become an integral part of diverse societal layers. As an engaging online gaming platform, games facilitate social interaction among players. One notable example is Genshin Impact, a mobile game also available on PC and PlayStation platforms. While the majority of society enjoys this game, some individuals feel less satisfied with their gaming experience. Sentiment analysis serves as a valuable tool for game developers to understand user opinions regarding the game. This research aims to develop a review classification model for Genshin Impact on Google Play, thus providing recommendations to HoYoverse Developers for further improvement.
Keywords: Sentiment Analysis, Genshin Impact, Nave Bayes
1. PENDAHULUAN
Game merupakan platform permainan online yang menarik, dimana para pemain masih dapat berinteraksi sosial secara daring melalui platfom game itu sendiri. Riset menunjukan bahwa terjadi peningkatan durasi bermain game sejak adanya regulasi pembatasan sosial[1]. Selain menjadi alternatif hiburan daring, game juga memiliki sisi negatif diantaranya menyebabkan kecanduan sehingga interaksi sosial didunia nyata menjadi terganggu. Bahkan efek negatif dari game dapat menyebabkan penggunanya menjadi antisosial[2].
Genshin Impact merupakan game mobile yang menyediakan platform lain seperti PC dan PlayStation. Game ini memadukan elemen action RPG dengan dunia terbuka yang indah dan menarik untuk dijelajahi[3]. Genshin Impact dirilis oleh HoYoverse pada tahun 2020[4]. Sejak perilisannya, Genshin Impact telah menjadi salah satu game mobile yang sangat populer di seluruh dunia, termasuk di Indonesia. Meskipun sebagian besar masyarakat menikmati permainan ini, ada pula yang merasa tidak sepenuhnya puas dengan pengalaman bermainnya. Analisis sentimen menjadi alat yang sangat berharga bagi pengembang game untuk memahami opini pengguna terhadap permainan tersebut. Penelitian ini bertujuan untuk membangun sebuah model klasifikasi ulasan terhadap Genshin Impact di Google Play, sehingga hasilnya dapat memberikan rekomendasi kepada Developer HoYoverse untuk perbaikan lebih lanjut. Analisis sentimen digunakan untuk menilai opini pengguna terhadap sebuah game, apakah dianggap positif, netral, atau negatif. Salah satu teknik umum dalam menganalisis sentimen adalah menggunakan machine learning, dimana algoritma Naive Bayes sering digunakan sebagai salah satu metodenya.
Naive Bayes adalah algoritma yang simpel dan umum digunakan untuk klasifikasi. Model klasifikasi Naive Bayes menghitung probabilitas posterior suatu kelas berdasarkan distribusi kata dalam dokumen, dengan mengandalkan representasi dokumen yang sederhana sebagai Bag of Words. Algoritma ini bekerja dengan mengekstraksi fitur Bag of Words yang mengabaikan posisi kata dalam dokumen. Dengan menggunakan Teorema Bayes, algoritma ini memprediksi probabilitas bahwa set fitur yang diberikan dimiliki oleh label tertentu. Penelitian ini bertujuan untuk membangun model klasifikasi ulasan tentang game Genshin Impact yang tersedia di platform Google Play. Diharapkan model yang dihasilkan dapat memberikan rekomendasi kepada pengembang untuk melakukan perbaikan. Selain itu, model ini juga bisa menjadi referensi bagi pengguna untuk mengevaluasi kinerja game Genshin Impact.
Video Game
Video game adalah suatu permainan yang dimainkan melalui manipulasi gambar elektronik yang diproduksi oleh program komputer dalam monitor atau tampilan layar lainnya. Jenis permainan ini menekankan pada permainan menggunakan tombol yang terhubung pada layar. Video game dapat diakses melalui banyak perangkat, mulai dari yang berbentuk konsol (Playstation, X-box, Sega, Dreamcast), komputer (baik off-line maupun on-line), serta gadget baik itu berupa tablet, smartphone dan lain-lain". Selain digunakan untuk menghibur diri dari kepenatan dan hal lain, video game juga berpotensi sangat besar sebagai media informasi yang sangat baik dilihat dari banyaknya orang yang suka bermain video game serta dimainkan tidak hanya usia muda tetapi kalangan dewasa juga, semua memainkan permainan video game.[5]
Nave Bayes Classifier
Naive Bayes Classifier adalah metode klasifikasi yang didasarkan pada Teorema Bayes. Metode ini menggunakan probabilitas dan statistik yang diajukan oleh ilmuwan Inggris Thomas Bayes, yang memungkinkan untuk memprediksi kemungkinan di masa depan berdasarkan pengalaman di masa sebelumnya. Karakteristik utama dari Naive Bayes Classifier adalah asumsi yang sangat kuat (naif) akan independensi dari setiap kondisi atau kejadian. Keunggulan utama dari metode ini adalah kemampuannya untuk melakukan klasifikasi dengan hanya memerlukan sedikit data pelatihan (training data) untuk mengevaluasi parameter-parameter yang diperlukan dalam proses klasifikasi.
Tahapan proses Naive Bayes
1. Menghitung jumlah kelas / label
2. Menghitung Jumlah Kasus Per Kelas
3. Kalikan Semua Variable Kelas
4. Bandingkan Hasil Per Kelas
Pada Teorema Bayes, bila terdapat dua kejadian yang terpisah (misalkan X dan H), maka Teorema Bayes dirumuskan sebagai berikut [6]:
Keterangan :
a. X : Data dengan class yang belum diketahui
b. H : Hipotesis data merupakan suatu class spesifik
c. P(H|X) : Probabilitas hipotesis H berdasar kondisi X (posteriori probabilitas)
d. P(H) : Probabilitas hipotesis H (prior probabilitas)
e. P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H
f. P(X) : Probabilitas X
2. METODE
Data yang dikumpulkan dalam penelitian ini diperoleh dari ulasan pengguna game Genshin Impact di Google Play Store dengan menggunakan library dari github.com/JoMingyu/google-play-scraper. Hasilnya kemudian dimanfaatkan untuk memperoleh data yang terstruktur dari berbagai sumber di Google Play Store, yang nantinya dapat diolah atau dianalisis lebih lanjut. Proses Pre-Processing teks dalam penelitian ini mencakup beberapa tahap, termasuk Transformasi Case untuk mengubah semua huruf kapital menjadi huruf kecil, Labeling untuk mengkategorikan sentimen berdasarkan nilai rating menjadi positif dan negatif, Tokenizing untuk memecah sekumpulan kalimat menjadi potongan kata-kata atau token, Filter tokens by length untuk menyaring data dengan panjang token minimal tertentu, Remove Punctuation untuk menghapus tanda baca, dan Pembobotan TF-IDF.
Setelah dataset melalui proses text pre-processing, selanjutnya adalah melakukan pembobotan pada teks tersebut untuk mendapatkan nilai agar bisa diklasifikasikan[8]. Pembobotan kata dalam dokumen dilakukan menggunakan salah satu metode yang populer, yaitu metode TF-IDF (Term Frequency-Inversed Document Frequency). Term Frequency berfokus pada seberapa sering sebuah istilah muncul dalam sebuah dokumen, sementara Inversed Document Frequency berfokus pada memberikan bobot terendah kepada istilah yang muncul dalam banyak dokumen.
Pengujian atau evaluasi menggunakan algoritma Naive Bayes yang menggunakan statistika sederhana berdasarkan teorema Bayes dengan memperkirakan keberadaan atau ketiadaan suatu kelas. Multinomial Naive Bayes adalah metode klasifikasi yang ditujukan untuk melakukan klasifikasi pada data tekstual. Metode ini memiliki fitur di mana hasil dari setiap kelas bersifat independen karena dokumen satu sama lain tidak memiliki keterkaitan, sehingga hasil yang diperoleh murni berasal dari dokumen tersebut sendiri.
1. Scrapping Data
Penelitian ini menggunakan proses Web Scraping untuk mengumpulkan data ulasan karena kemudahannya. Web scraping memiliki keunggulan karena memungkinkan para peneliti untuk mengakses kumpulan data baru yang belum diakses sebelumnya, tanpa memerlukan dana untuk membeli peralatan mahal atau mengkompensasi peserta. Intinya, web scraping adalah tentang mendapatkan data dengan mengambil dan mengekstraksi informasi dari berbagai sumber dengan ukuran data yang beragam. Untuk mengumpulkan data ulasan permainan ini dari Google Play Store, penulis menggunakan teknik scraping data dengan menggunakan kode dari https://github.com/JoMingyu/google-play-scraper. Ekstensi ini membantu dalam mengambil data ulasan secara otomatis tanpa perlu melakukan secara manual. Data ulasan yang dikumpulkan berasal dari website Google Play Store tentang ulasan permainan Genshin Impact, yang dapat diakses melalui tautan https://play.google.com/store/apps/details?id=com.miHoYo.GenshinImpact. Setelah proses scraping selesai, data dapat diunduh dari laman tersebut. Data ulasan tersebut dapat disimpan dalam format csv atau excel di komputer. Selanjutnya, penelitian ini melakukan analisis dengan melakukan klasifikasi data ulasan pengguna untuk mengidentifikasi ulasan positif dan negatif menggunakan metode Nave Bayes Classifier.
2. Preprocessing Data
2.1 Pelabelan Data
Data diberi label dengan membaginya menjadi tiga kelas: positif, negatif, dan netral. Proses pelabelan dilakukan secara otomatis menggunakan Python, sesuai dengan rating (bintang) yang diberikan oleh pengguna game Genshin Impact yang telah diambil dari halaman website Google Play.
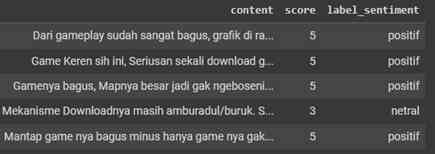
2.2 Mengubah menjadi huruf kecil
Mencakup pengubahan seluruh huruf menjadi huruf kecil, adalah langkah penting dalam analisis sentimen review aplikasi. Dengan normalisasi, teks dari ulasan pengguna akan seragam dalam formatnya, mempermudah proses analisis dan klasifikasi. Dengan demikian, perbedaan huruf besar kecil tidak akan mempengaruhi hasil akhir, dan algoritma analisis sentimen dapat lebih efektif dalam mengidentifikasi pola dan sentimen yang mendasari ulasan pengguna. Ini adalah langkah awal yang penting dalam mempersiapkan data untuk proses analisis lebih lanjut.
2.3 Data Cleaning
Proses cleaning data, yang meliputi penghapusan tanda baca dan penggunaan stopwords dari Sastrawi. Dengan menghilangkan tanda baca, teks ulasan menjadi lebih bersih dan lebih mudah diproses oleh algoritma analisis. Selain itu, penggunaan stopwords dari Sastrawi membantu menghilangkan kata-kata yang umumnya tidak memberikan kontribusi signifikan terhadap pemahaman sentimen, sehingga meningkatkan akurasi dalam mengidentifikasi sentimen yang sebenarnya dalam ulasan pengguna.
2.4 Tokenization
Tokenization adalah tahap penting dalam analisis sentimen review aplikasi di mana teks ulasan dibagi menjadi unit-unit yang lebih kecil yang disebut token. Token dapat berupa kata, frasa, atau karakter terpisah, tergantung pada metode tokenisasi yang digunakan. Dengan tokenization, teks ulasan dapat dipecah menjadi bagian-bagian yang lebih terstruktur, memungkinkan analisis lebih lanjut seperti pembentukan model atau perhitungan statistik. Dengan memiliki teks yang sudah dipisahkan ke dalam token, proses analisis sentimen dapat dilakukan dengan lebih efisien dan akurat.

2.5 Stemming
Stemming dilakukan untuk mengubah kata-kata dengan imbuhan menjadi bentuk dasarnya, dengan asumsi bahwa makna kata tersebut tetap sama. Hal ini bertujuan untuk mempermudah pembobotan kata dalam proses analisis. Meskipun proses ini memerlukan waktu yang cukup lama saat dijalankan menggunakan Python, hal tersebut tergantung pada jumlah kalimat atau kata yang diproses dalam dokumen. Proses stemming menggunakan library NLP (Natural Language Programming) dalam bahasa Indonesia, yaitu Sastrawi. Penggunaan Sastrawi dipilih karena meskipun sederhana, library tersebut tetap dianggap berkualitas dan memiliki dokumentasi yang baik.
3. Pembobotan TF-IDF
Pembobotan TF-IDF (Term Frequency-Inverse Document Frequency) adalah teknik yang digunakan untuk mengevaluasi pentingnya suatu kata dalam sebuah dokumen dengan memberikan nilai bobot pada setiap kata tersebut. Metode ini telah menjadi favorit karena tingkat akurasinya yang tinggi, memungkinkan pembobotan kata dilakukan secara efektif dan efisien dengan hasil yang memuaskan. Dalam penelitian ini, penulis memanfaatkan sebuah library dalam bahasa Python yang menyediakan rumus TF-IDF, yaitu TfidfVectorizer.
4. Klasifikasi Nave Bayes Classifier
Dalam proses klasifikasi menggunakan NBC (Nave Bayes Classifier), pengklasifikasian dilakukan dengan memanfaatkan metode probabilitas dan statistik untuk menghasilkan akurasi klasifikasi dokumen yang telah diolah. Penelitian ini menerapkan algoritma Nave Bayes Classifier dengan menggunakan metode Multinomial Nave Bayes. Metode ini terbukti efektif dalam menghitung frekuensi kemunculan setiap kata dalam suatu dokumen, sehingga memungkinkan untuk melakukan klasifikasi dengan akurat. Multinomial Nave Bayes digunakan karena algoritma ini memiliki beberapa keunggulan, yaitu memiliki tingkat akurasi yang tinggi, mudah untuk diimplementasikan, memakan waktu komputasi yang rendah, dan error state yang minimum.[7]
5. Pembagian Data Train dan Data Test
Dalam proses pembagian data menjadi data latih (training) dan data uji (test), dilakukan pembentukan model klasifikasi. Hal ini bertujuan agar informasi yang dihasilkan dari data pelatihan dan data uji dapat digunakan untuk memprediksi kelas data baru dengan akurasi yang tinggi. Dengan membagi data menjadi dua bagian ini, model klasifikasi dapat diuji dan dievaluasi keefektifannya dalam mengklasifikasikan data yang belum pernah dilihat sebelumnya.
6. Evaluasi
Pada tahap evaluasi, beberapa langkah dijalankan, di antaranya adalah pembuatan Confusion Matrix untuk mengevaluasi kinerja NBC (Nave Bayes Classifier). Langkah ini penting untuk mengukur Recall, Precision, Accuracy, dan F-Measure. Confusion Matrix membantu dalam memberikan gambaran yang jelas tentang seberapa baik model klasifikasi dapat mengklasifikasikan data dengan benar dan menganalisis performanya secara rinci.
7. Testing
Dalam tahap testing, saya menggunakan model klasifikasi yang telah dibuat untuk memprediksi apakah suatu kalimat termasuk dalam kategori negatif atau positif, berdasarkan pada data yang telah diproses sebelumnya. Langkah ini melibatkan memasukkan kalimat ke dalam model dan menganalisis keluaran prediksi yang dihasilkan. Proses ini memungkinkan untuk mengevaluasi seberapa baik model dapat membedakan antara kalimat negatif dan positif, serta mengukur keakuratannya dalam melakukan prediksi.
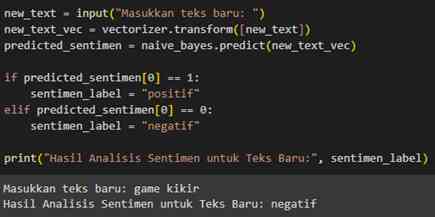
3. HASIL DAN PEMBAHASAN
1. Evaluasi Algoritma Nave Bayes
Penelitian ini dilakukan pembagian data uji dan data latih sebanyak 70:30
1.1 Confusion Matrix
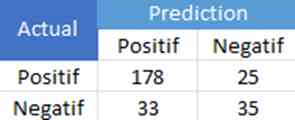
Dalam rangkaian uji pertama, di mana 70% dari data digunakan sebagai data pelatihan dan 30% sebagai data uji, ditemukan bahwa dari total 271 data uji, sebanyak 178 data yang diprediksi dengan benar sebagai sentimen positif, sesuai dengan kebenaran sebenarnya. Namun, terdapat 33 data ulasan positif yang salah diprediksi oleh model. Sementara itu, untuk ulasan negatif, model berhasil memprediksi dengan benar sebanyak 25 data sebagai ulasan negatif, tetapi 35 data lainnya diprediksi secara salah oleh model.
1.2 Recall
Pada tahap ini, recall digunakan untuk mendapatkan perbandingan antara jumlah prediksi positif data ulasan yang benar dibandingkan dengan keseluruhan data yang diprediksi positif.
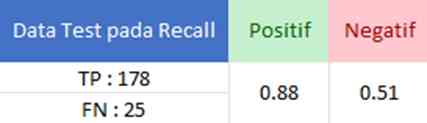
Dari tabel yang disajikan, didapatkan hasil True Positive (TP) sebanyak 178 data, False Negative (FN) sebanyak 25 data. Nilai recall untuk rangkaian pertama ini adalah 0.88 untuk kategori positif dan 0.51 untuk kategori negatif.
1.3 Precision
Tahap evaluasi Precision dilakukan untuk mendapatkan perbandingan dari jumlah data diprediksi positif benar oleh model dibandingkan dengan keseluruhan data yang positif.
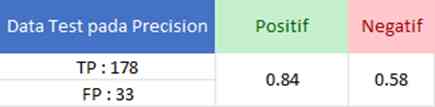
Dari tabel yang disajikan, didapatkan hasil True Positive (TP) sebanyak 178 data, False Negative (FN) sebanyak 33 data. Nilai precision untuk rangkaian pertama ini adalah 0.84 untuk kategori positif dan 0.58 untuk kategori negatif.
1.4 F1-Score
Pada tahap evaluasi F1-Score, perhitungan evaluasi ini digunakan untuk membandingkan rata-rata precison dan recall yang telah dibobotkan.
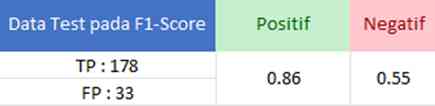
Dari tabel yang disajikan, terdapat hasil True Positive (TP) sebanyak 178 data dan False Negative (FN) sebanyak 33 data. Nilai F1-Score untuk rangkaian pertama ini adalah 0.86 untuk kategori positif dan 0.55 untuk kategori negatif.
1.5 Accuracy
Pada tahap ini akan dilakukan perbandingan pada akurasi kedua rangkaian untuk menilai akurasi dari hasil algoritma yang dilakukan.
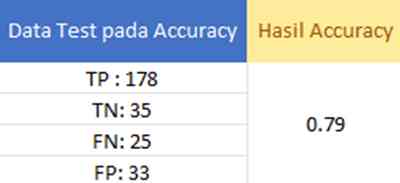
Dari tabel yang disajikan, didapatkan hasil True Positive (TP) sebanyak 178 data, True Negative (TN) sebanyak 35 data, False Negative (FN) sebanyak 25 data, dan False Positive (FP) sebanyak 33 data. Hasil akurasi untuk rangkaian pertama ini adalah 0.87.
2. Analisis Hasil dan Visualisasi
2.1 Visualisasi Word Cloud Positif
Word Cloud untuk ulasan kelas positif dapat dilihat pada gambar berikut. Visualisasi ini menampilkan kata-kata yang sering muncul dalam ulasan tersebut untuk memudahkan pengamatan terhadap pola dominan.

2.2 Visualisasi Word Cloud Negatif
Word Cloud untuk ulasan kelas negatif dapat dilihat pada gambar berikut. Visualisasi ini menampilkan kata-kata yang sering muncul dalam ulasan tersebut untuk memudahkan pengamatan terhadap pola dominan.

2.3 Jumlah Kata yang Paling Sering Muncul
Menggunakan python untuk menghitung kata apa yang paling sering muncul
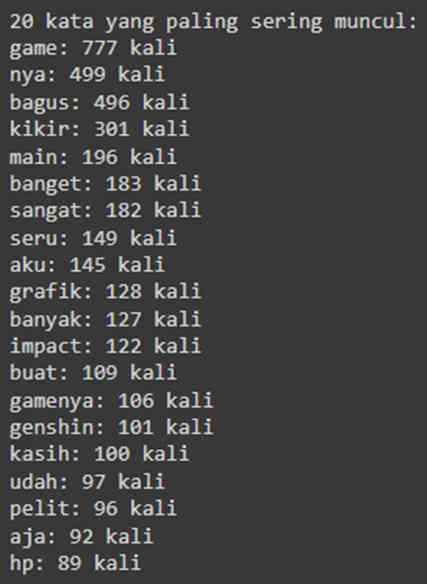
Bisa dilihat, walaupun kata-kata positif memang mendominasi, namun kata-kata negatif juga tidak kalah banyak, seperti "kikir dan pelit" yang memang benar adanya karena saya sendiri memainkan game nya, dan di forum seperti Facebook dan Reddit memang banyak pemain yang mengeluhkan seberapa pelit dan tidakpedulinya developer HoYoverse ini kepada pemainnya.
4. KESIMPULAN
Berdasarkan klasifikasi yang telah dilakukan, menunjukkan bahwa metode Naive Bayes terhadap analisis sentiment aplikasi Genshin Impact memiliki hasil klasifikasi dengan akurasi cukup tinggi yaitu accuracy 0,79. Walaupun beberapa pemain Genshin Impact sudah merasa cukup puas dengan kualitas game ini, namun berdasarkan review pengguna, kata-kata seperti "kikir dan pelit" terdapat di banyak ulasan, sehingga HoYoverse sebagai developer seharusnya segera menindaklanjuti masukan beberapa pemain mereka sehingga mereka bisa betah untuk tetap memainkan game mereka.
DAFTAR PUSTAKA
[1] D. L. King, P. H. Delfabbro, J. Billieux, and M. N. Potenza, "Problematic online gaming and the COVID-19 pandemic," J. Behav. Addict., vol. 9, no. 2, pp. 184--186, 2020.
[2] R. J. Santi, D. Setiawan, and I. A. Pratiwi, "Perubahan Tingkah Laku Anak Sekolah Dasar Akibat Game Online," J. Penelit. dan Pengemb. Pendidik., vol. 5, no. 3, p. 385, 2021.
[3] A. Zahraputeri and L. Kusdibyo, "Analisis Persepsi Pemain Terhadap Game CrossPlatform: Studi Kasus Permainan Genshin Impact," Pros. 12th Ind. Res. Work. Natl. Semin., pp. 1273--1278, 2021.
[4] C. Angelia, F. A. M. Hutabarat, N. Nugroho, Arwin, and Ivone, "Perilaku Konsumtif Gamers Genshin Impact terhadap Pembelian Gacha," J. Bus. Econ. Res., vol. 2, no. 3, pp. 61--65, 2021.
[5] C. Angelia, F. A. M. Hutabarat, N. Nugroho, Arwin, and Ivone, "Perilaku Konsumtif Gamers Genshin Impact terhadap Pembelian Gacha," J. Bus. Econ. Res., vol. 2, no. 3, pp. 61--65, 2021.
[6] Bustami, Bustami. "Penerapan algoritma Naive Bayes untuk mengklasifikasi data nasabah asuransi." TECHSI-Jurnal Teknik Informatika 5, no. 2 (2013).
[7] N. A. Vidya, "Opinion Mining Dengan Menggunakan Multinomial Naive Bayes Classifier Pada Blog," Tek. Inform., pp. 1--55, 2012.
Follow Instagram @kompasianacom juga Tiktok @kompasiana biar nggak ketinggalan event seru komunitas dan tips dapat cuan dari Kompasiana. Baca juga cerita inspiratif langsung dari smartphone kamu dengan bergabung di WhatsApp Channel Kompasiana di SINI
