


















PT Zona Edukasi Nusantara (Zenius) bersama Kampus Merdeka Batch 3 membuka Program Zenius Studi Independen Bersertifikat (PZIB). Saya Ama Febriyanti, mahasiswa prodi S1 Akuntansi Universitas Negeri Malang berkesempatan bergabung dalam program tersebut. Saya diterima di learning path Data analytics dengan Kak Hariyanto Wicaksono selaku mentor. Dalam pelaksanaannya, saya juga mendapatkan bimbingan dari Dosen dari kampus saya yaitu Bapak Tomy Rizky Izzalqurny, S.E., M.S.A. CBV, CAP. Dalam kesempatan ini, saya akan membagikan pengetahuan yang saya peroleh melalui penugasan Topic 19 - Assignment | Rancangan Use Case Data Science. Dalam penugasan ini, saya membuat use case klusterisasi resiko kredit kustomer.
Perbankan menurut Undang-undang Nomor 10 Tahun 1998 tentang Perbankan, merupakan badan usaha yang menghimpun dana dari masyarakat dalam bentuk simpanan dan menyalurkannya kepada masyarakat dalam bentuk kredit dan atau bentuk-bentuk lainnya dalam rangka meningkatkan taraf hidup masyarakat. Saat ini, data telah menjadi aset paling berharga di bidang ini. Untuk itu, ilmu data akan sangat bermanfaat ketika digunakan misalnya dalam hal, analisis resiko investasi, prediksi nilai lifetime customer, segmentasi customer, prediksi churn rate customer dan yang paling umum adalah untuk mendeteksi fraud atau penipuan.
Salah satu manfaat ilmu data adalah mendeteksi resiko kredit customer. Hal ini penting untuk menganalisis historis perilaku kredit peminjam. Dengan memahami faktor-faktor yang berkontribusi pada kemungkinan gagal bayar peminjam, bank dapat membuat keputusan secara lebih tepat tentang siapa yang akan dipinjami uang, berapa banyak yang akan diperpanjang, dan kapan harus menarik kembali. Penggunaan alogaritma data analysis akan sangat mempermudah dalam hal ini karena dapat secara otomatis mengidentifikasi pola dalam data yang tidak dapat dilihat manusia. Berikut merupakan rancangan use case untuk mendeteksi credit risk.
Data Understanding
Dalam rancangan use case ini digunakan dataset Geman Credit Risk dengan format csv yang diambil dari kaggle (Dataset German Credit Risk). Dataset tersebut berisi informasi mengenai 1000 orang Jerman, batas kredit, dan pinjaman, serta sembilan parameter yang berbeda seperti usia, jenis kelamin, pekerjaan, perumahan dll. Setiap baris mewakili orang yang telah mengambil pinjaman. Adapun variabel dalam data ini antara lain: Age (Usia peminjam atau customers), Sex (Jenis kelamin peminjam / male or female), Job (Pekerjaan peminjam), Housing (Tipe Rumah), Saving accounts (Jenis tabungan yang menunjukan kecenderungan peminjam untuk menabung), Checking account (Saldo di rekening giro (Mata Uang: DM - Deutsche Mark)), Credit amount (Batas kredit yang digunakan oleh pemegang rekening), Duration (durasi pinjaman dalam bulan), dan Purpose (Tujuan penggunaan pinjaman). Sasaran use case ini adalah untuk mengidentifikasi resiko pinjaman dari customers dan mengklasifikasikannya menjadi Good dan Bad dimana,
- Good: Resiko baik dari perspektif bank dan lebih mungkin memulihkan pinjaman.
- Bad: Resiko buruk dari perspektif bank dan kecil kemungkinannya untuk memulihkan pinjaman, lebih banyak kemungkinan gagal bayar.
Data Preparation
Tahap selanjutnya adalah menyiapkan data yaitu, pertama dengan mengimportnya terlebih dahulu ke IDE for python yaitu google colabs untuk di analisis dan dibersihkan terlebih dahulu. Dari proses tersebut diketahui bahwa lebar data adalah 9 kolom dan 1000 baris. Dengan lima variabel bertipe object atau data categorical dan empat variabel dengan tipe integer atau data nominal. Setelah itu, dilanjutkan dengan data cleansing yaitu mengecek data null terlebih dahulu. Kemudian diketahui bahwa Masih ada data yang kosong yaitu pada kolom saving accounts dan checking accounts. Setelah itu, dilakukan missing handle dengan mengisi data kosong dengan “unknown” atau menunjukkan bahwa informasi data tidak diketahui.
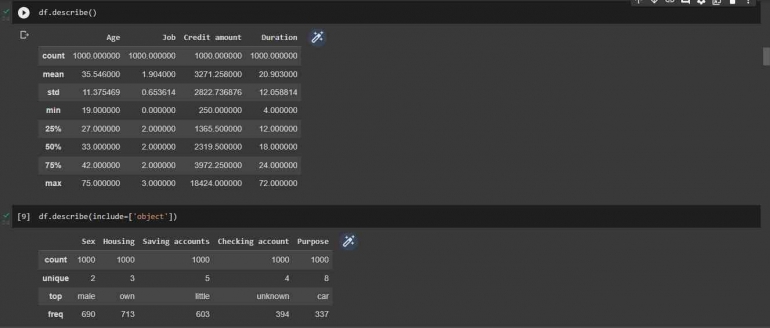
Kemudian, berikut merupakan deskripsi dari dataset, baik variabel nominal maupun categorical,
Berikut merupakan visualisasi distribusi dari masing-masing variabel nominal:
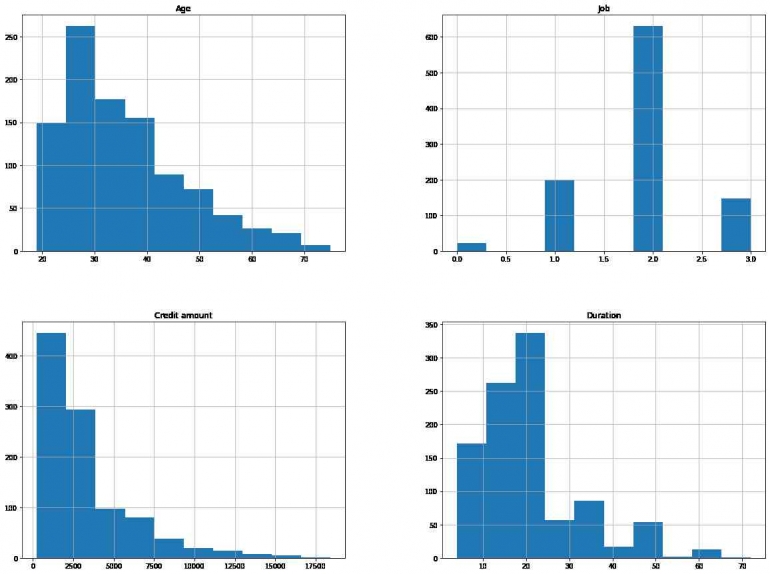
- Pada grafik age/umur terjadi pelonjakan kenaikan dari umur 20 ke 25 dan dari 25 sampai 40 merupakan umur yang dengan jumlah terbanyak dan semakin tua umurnya semakin menurun grafik
- Pada grafik job label 2 mendominasi dengan jumlah >600
- Pada grafik Credit amount paling banyak yaitu pada jumlah credit amount 0-3000 dan untuk semakin besar credit amount semakin sedikit jumlahnya juga
- Pada grafik duration didapatkan durasi yang paling banyak diambil oleh nasabah yaitu dengan durasi 2-25 bulan, untuk yang lebih dari itu juga ada tetapi terdapat perbedaan grafik yang cukup berbeda signifikan lebih sedikit.
